I’ve been reading and thinking recently about the potential for a tragedy of the commons to be a reality in the realm of open source. The tragedy of the commons is a economic theory that says that individuals behave contrary to the self-interest of everyone by depleting a common resource. One needs to look no further than the environment for examples of this behavior.
Free and Open Source Software
Free and Open Source software has revolutionized how the world consumes software. Linux, BSD, httpd, nginx, MySQL, PostgreSQL, and thousands of other software products are consumed voraciously. But almost universally people are only consuming. And generally that’s okay. Sharing is one of the key tenets and strengths – that we are able to freely share code to help our neighbor.
Of course we can’t deny that it has a downside? We’ve of course seen the outrage and shock following the Heartbleed vulnerability that only 4 people were watching and contributing to one of the most widely used cryptography libraries in the world.
This past week, the coverage of the GPG suite of tools being basically unfunded broke. Unfortunately it took that level of shaming for folks to realize that it was important and supply some money to fund a developer or two to work on the project. Of course I am as guilty as anyone – I’ve used GPG for years to protect private communications, to sign software releases, and a few other purposes. And before that I’ve used OpenSSL for years to protect web traffic. However, until this past week, I hadn’t contributed a cent directly to any of those efforts.
Technical Debt
The issue though is really larger than just security or a few ‘critical infrastructure’ projects. The reality is that we, and especially businesses, are incurring an odd kind of technical debt for every piece of free and open source software that we are using. If we aren’t actively contributing to a project, we are hoping that others will. We are putting our trust in the fact that someone will find it valuable enough to contribute, even when we don’t.
Recently, one of the members of the Apache Software Foundation’s infrastructure staff, Daniel Gruno, did some research into open source project health. He invented a humorous name, termed the ‘Pony Factor’ to represent the lowest number of contributors to a codebase to contribute 50% of the codebase. And then realizing that people come and go from open source projects, he developed an ‘Augmented Pony Factor’ calculation that takes into account only active developers.
He started by looking at projects at the Apache Software Foundation. The below graphic shows the lowest number of individual contributors who contributed to an Apache Project’s codebase. Obviously that graphic only lists a few of them. If you want to see all of the current projects from the Apache Software Foundation, you can see that graph here.

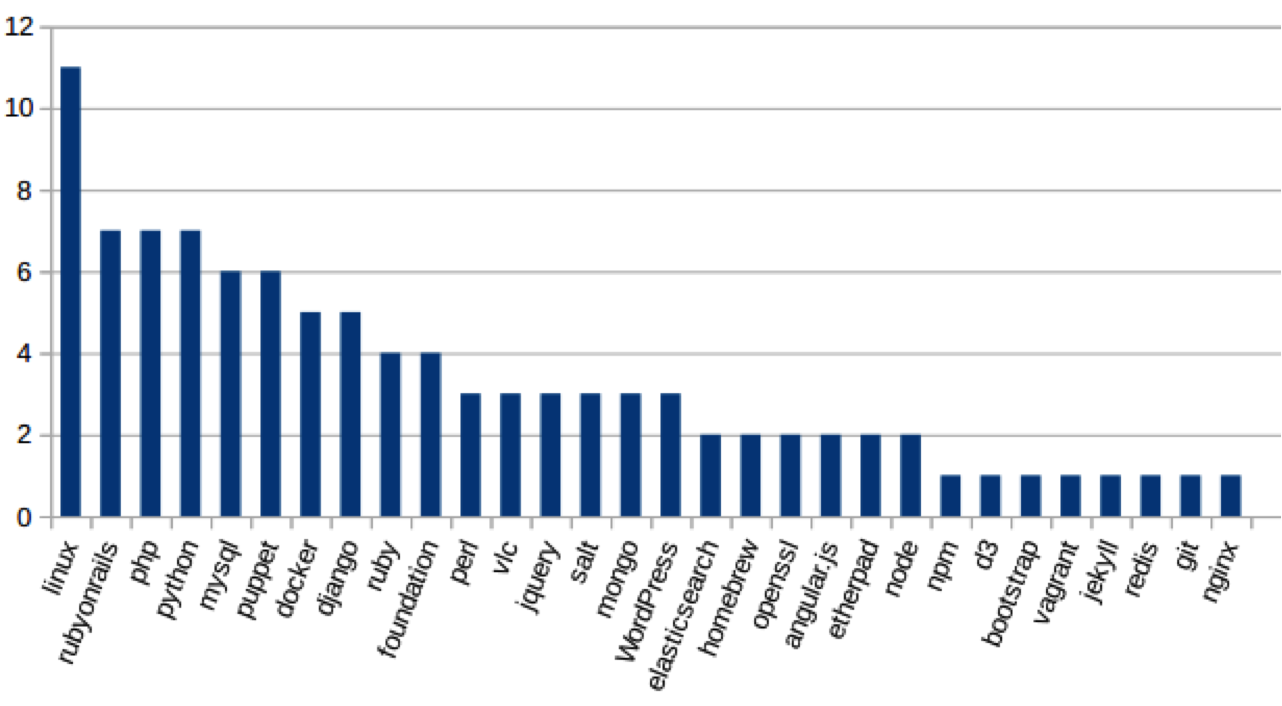
But, in a vacuum that’s hard to know if those numbers are good or not, so Daniel went beyond that and looked at a handful of popular free and open source projects:
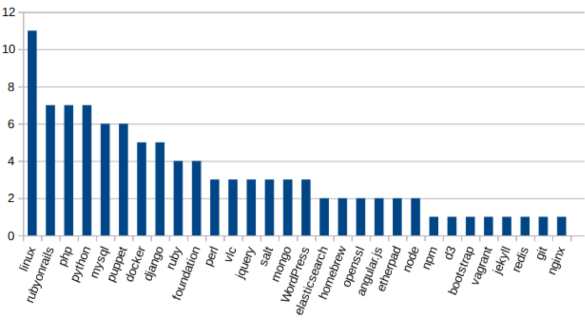
I was shocked by seeing some of those statistics. Do I feel comfortable that only three people are actively contributing 50% of the current code contributions to the blog software this post appears on? Or that one person writes most of my preferred version control platform. Am I willing to trust my business to that? And of course we know that state security agencies have NEVER asked free and open source developers to compromise security.
How do we avert a tragedy?
The first issue is that we need to be aware of the risk. Many of us see the incredible platforms out there and simply trust that the people who wrote them knew best and are going to continue to provide us with great software. As one of my favorite authors quipped in his novel, TANSTAAFL.
“Gospodin,” he said presently, “you used an odd word earlier–odd to me, I mean…”
“Oh, ‘tanstaafl.’ Means ~There ain’t no such thing as a free lunch.’ And isn’t,” I added, pointing to a FREE LUNCH sign across room, “or these drinks would cost half as much. Was reminding her that anything free costs twice as much in long run or turns out worthless.”
“An interesting philosophy.”
“Not philosophy, fact. One way or other, what you get, you pay for.”
I am not advocating for paying for every piece of software or needing to contribute to every open source project in existence, but I’ll leave you with this question. What are you doing to avert a tragedy of the free and open source commons? And if you aren’t, then who will?